User:ErsatzCulture/ISFDBCheckerWebExtension
ISFDBChecker is an open source WebExtension and related Python daemon, that alters your web browsing experience to highlight publications that are not in the ISFDB database and/or unknown to the Fixer robot.
On any webpage, the browser extension examines all hyperlinks - which could be regular hyperlinks with a text label, or images that are linked to another page. If the hyperlink contains something that looks like an ISBN10, ISBN13 or ASIN, it sends an HTTP request to the daemon process, with a payload containing all of those ISBNs and ASIN.
The daemon has all the ISBNs and ASINs present in the ISFDB database and Fixer datastories loaded into memory. It checks all the received ISBNs and ASINs, and any which are not known are returning in the HTTP response to the browser extension.
If there are any unknown ISBNs or ASINs, the browser extension will highlight these in the page in either pink (completely unknown) or purple (not in the database, but known to Fixer).
How that information is acted upon is a separate issue...
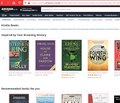
Amazon UK
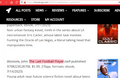
Locus New Books list

Gollancz

Server log



This approach is far from perfect:
- You get false positives e.g. if a hyperlink contains a 10 or 13 digit number that is not an ISBN
- Some URL forms that do contain ISBNs are not currently recognized e.g. http://somewebsite.com/page?isbn=9781234567890
- Some websites do not use a URL scheme that embeds an ISBN or ASIN in the URL e.g. Kobo, Titan Books. However a surprising amount do
- Non-genre books are obviously going to be picked up; this can be annoying if you do a lot of browsing of such webpages
- ISBNs or ASINs that are in the page text, but not a hyperlink, will not be recognized. It is possible that they may be supported in future though
- Hyperlinks that are injected into the page after initial page load will not be checked. (This includes some, but far from all, of the "Users also bought" recommendations you get on Amazon, for example.)
However, it provides an alternative to the Amazon scraping+.com approach used by Fixer, which helps highlight pubs that the former fails to catch.
Installation
Pull the repo from GitHub: https://github.com/JohnSmithDev/ISFDB-Tools The WebExtension and Python daemon are in the isfdb_checker subdirectory.
Dependencies
- Downloaded copies of the weekly ISFDB database and Fixer XML backups, ideally as current as possible
- For the database backup, it needs to be installed and accessible. For what it's worth, once the daemon has initialized all the data, the database is no longer accessed
- For the Fixer XML, the zip file needs to be unpacked in a known location
- Some form of SSL certificates, if HTTPS is being used. Locally generated certificates are fine - and are used by the developer of these tools - but have the annoying problem of expiring one week after generation.
- Probably some sort of Python 3 virtualenv
- Various PyPy packages e.g. gunicorn
Browser WebExtension
This should be usable in any web browser that supports the WebExtension standard. Browsers usually have some sort of "load unpacked extension" facility, intended for use by software developers, but which can be used by any browser user.
Note that currently there is some configuration that needs to be hacked in; if there is interest from others in running this extension, a proper UI can be easily added
Python Daemon
This can be run a couple of different ways, depending on what version of Python and packages is installed. One variant is via gunicorn, as follows:
gunicorn -w 4 --access-logfile=- --certfile cert.pem --keyfile key.pem -b 0.0.0.0:5000 tools.id_checker:app